上文讲到了wordCount示例程序运行时的启动流程,依旧停留在框架理解上。下面开始详细介绍一下Spark Streaming中是如何接收和存储流数据。实际应用中Streaming的输入源有多种,这里仍旧以wordCount为例,对socketStream进行介绍。
源码跟踪
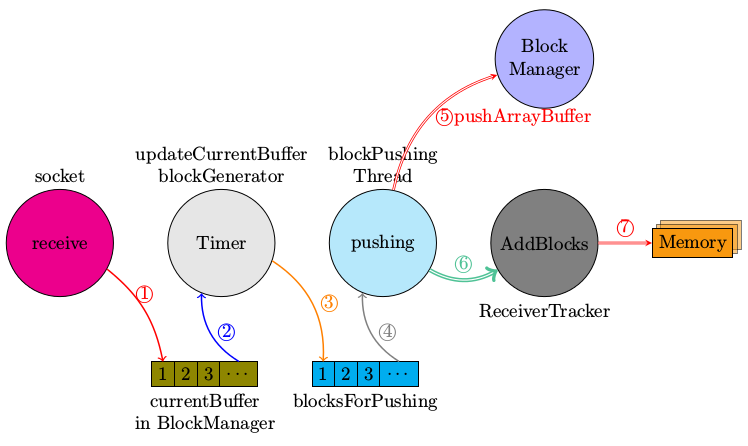
上文中StartReceivers中实例化了一个ReceiverSupervisorImpl对象,然后启动之。ReceiverSupervisorImpl继承自ReceiverSupervisor,实现了ReceiverSupervisor中处理接收数据的方法。这里executor.start()中的start方法是继承自ReceiverSupervisor,调用了onStart和startReceiver两个方法。继续看startReceiver方法:
终于看到启动receiver的关键代码了,可是onStart和onReceiverStart方法其实是在ReceiverSupervisorImpl类中实现的,我们看看代码:
|
|
|
|
接着看BlockGenerator中的start方法:
|
|
接下来,看看blockPushingThread乃何方神圣:
|
|
调用了一个叫keepPushingBlocks的方法,继续往根上刨:
|
|
接着看关键的pushBlock方法,pushBlock调用onPushBlock方法
|
|
这里并没有具体实现,具体实现其实在ReceiverSupervisorImpl中实例化BlockGenerator时:
|
|
由此,继续刨根问底,看pushArrayBuffer方法:
|
|
至此,流数据接收并存储起来,然后将block的id,大小和元数据信息发送给dirver以供调度时使用。